企業情報
(current)
サービス
(current)
API
(current)
ニュース
(current)
お問い合わせ
(current)
すべて
新着情報
プレスリリース
2024.02.27
イベント
メタデータ、「AI博覧会」に、大規模社内知識を生成AIに適切に回答させる製品ChatBridを出展
2024.02.08
イベント
データマネジメント2024でJDMC「生成AIを活用したデータ管理・クレンジング研究会」リーダのメタデータ野村社長が講演
2024.02.05
イベント
第8回 ジェネレーティブAI勉強会でメタデータ野村社長が講演『RAGを高精度に保ちつつ大規模化する仕組みおよび言語学的知見について』
2024.02.01
イベント
日本ナレッジマネジメント学会・第65回知の創造研究部会でメタデータ野村社長が招待講演『生成AIが駆動するKMの新動向と人間との価値共創の展望』
2024.01.29
プレスリリース
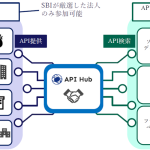
メタデータ、SBIデジタルハブのAPI Hubに性格診断APIを提供 ~GPTs市場の対話アプリ差別化に好適
2023.11.07
イベント
メタデータCTO常務兼Livie’s Jump代表・松田圭子氏がスクエアfreeセミナー第148回 「生成AIのコモディティ化で進むAI活用」に登壇
2023.11.06
イベント
メタデータCTO常務兼Livie’s Jump代表・松田圭子氏がデブサミウーマン2023に登壇
もっと見る
2024.02.27
イベント
メタデータ、「AI博覧会」に、大規模社内知識を生成AIに適切に回答させる製品ChatBridを出展
2024.02.08
イベント
データマネジメント2024でJDMC「生成AIを活用したデータ管理・クレンジング研究会」リーダのメタデータ野村社長が講演
2024.02.05
イベント
第8回 ジェネレーティブAI勉強会でメタデータ野村社長が講演『RAGを高精度に保ちつつ大規模化する仕組みおよび言語学的知見について』
2024.02.01
イベント
日本ナレッジマネジメント学会・第65回知の創造研究部会でメタデータ野村社長が招待講演『生成AIが駆動するKMの新動向と人間との価値共創の展望』
2023.11.07
イベント
メタデータCTO常務兼Livie’s Jump代表・松田圭子氏がスクエアfreeセミナー第148回 「生成AIのコモディティ化で進むAI活用」に登壇
2023.11.06
イベント
メタデータCTO常務兼Livie’s Jump代表・松田圭子氏がデブサミウーマン2023に登壇
2023.11.02
イベント
デジタルドキュメント2023ウェビナーでメタデータ野村社長が特別講演:『マニュアルの社内知識や商品知識をchatGPTに人間以上に親切・適切に回答させる』
2023.10.26
イベント
みんなのケア情報学会 第6回年次大会(CIHCD2023)でメタデータ松田取締役がChatBridを活用したメンタルケア対話ボット「やわらかネコ」について発表
2023.05.23
イベント
JIIMAウェビナーでメタデータ野村社長が特別講演:『「これからの文書情報マネジメント」にChatGPTのような生成系AIがどのように役立つか』
2021.12.22
お知らせ
HL2021のメタデータ賞について
もっと見る
2024.02.27
イベント
メタデータ、「AI博覧会」に、大規模社内知識を生成AIに適切に回答させる製品ChatBridを出展
2024.02.08
イベント
データマネジメント2024でJDMC「生成AIを活用したデータ管理・クレンジング研究会」リーダのメタデータ野村社長が講演
2024.02.05
イベント
第8回 ジェネレーティブAI勉強会でメタデータ野村社長が講演『RAGを高精度に保ちつつ大規模化する仕組みおよび言語学的知見について』
2024.02.01
イベント
日本ナレッジマネジメント学会・第65回知の創造研究部会でメタデータ野村社長が招待講演『生成AIが駆動するKMの新動向と人間との価値共創の展望』
2024.01.29
プレスリリース
メタデータ、SBIデジタルハブのAPI Hubに性格診断APIを提供 ~GPTs市場の対話アプリ差別化に好適
2023.11.07
イベント
メタデータCTO常務兼Livie’s Jump代表・松田圭子氏がスクエアfreeセミナー第148回 「生成AIのコモディティ化で進むAI活用」に登壇
2023.11.06
イベント
メタデータCTO常務兼Livie’s Jump代表・松田圭子氏がデブサミウーマン2023に登壇
2023.11.02
イベント
デジタルドキュメント2023ウェビナーでメタデータ野村社長が特別講演:『マニュアルの社内知識や商品知識をchatGPTに人間以上に親切・適切に回答させる』
2023.10.31
プレスリリース
メタデータCTO常務兼Livie’s Jump代表・松田圭子氏、みんなのケア情報学会大会インタラクティブセッションで最優秀賞を受賞
2023.06.14
プレスリリース
メタデータ、「ChatGPTを法人、組織で活用するためのガイドライン」を提供開始
もっと見る
事業情報
開発サービス
開発API
企業情報
会社概要
採用情報
お問い合わせ
Contact
弊社のサービス・APIについてお気軽にご連絡・ご相談ください
> お問い合わせはこちらから <